真不是炼丹,务实敢为的 MoCo v3 |
您所在的位置:网站首页 › moco v1 v2 v3 › 真不是炼丹,务实敢为的 MoCo v3 |
真不是炼丹,务实敢为的 MoCo v3

作者 | 黄挂 编辑 | NewBeeNLP 这次分享的paper是 An Empirical Study of Training Self-Supervised Visual Transformers[1] ,前不久刚挂出来了的,可谓新鲜滚热辣了。
这篇paper是 FAIR 何凯明的 MoCo-v3,行文还是很务实的,开篇第一句:“This paper does not describe a novel method”,明讲没有新方法,只是手把手教你如何训练visual transformer的。所以这篇paper更像是一篇实验报告。 Take Away因为我也经常看别人的论文阅读笔记,其实不喜欢那种整篇顺一遍几乎没有提炼的笔记。但其实会议通货膨胀,很容易遇到水文,我想每篇阅读笔记最前面都写一些take away,大家可以最方便快捷的了解到自己需不需要继续了解这篇文章。 不过我总是建议大家多读读paper,毕竟作者能把实验思想写成paper发表,再水也总是有可取之处的。下面是这篇文章的 take away: 水文指数(满分5):⭐️(十分值得一读) ViT 这个结构最近很火,但自监督训练会有不稳定的情况,可以通过冻结住第一层的 patch 层(随机参数)来缓解。 如何debug自监督模型:kNN curve + 监控gradient magnitude。 抛开文章提出的idea本身,我觉得作者在paper里体现的思考过程是更可学习的,体现出顶级研究者的不同之处,也是我对这篇paper评价很高的原因。毕竟授人以鱼不如授人以渔。大家可以往下看细品,具体下面“如何思考”的小节。 简介这篇文章就讲一个事情:「如何训练一个visual transformer」。 回归最基本的一些东西:learning rate、batch size、optimizer这些。他们是从 self-supervised 的角度来研究 ViT 的训练的,「发现关键因素是 instability」。也就是 ViT 的训练可能会容易不稳定。 而且有趣的是,不稳定的 ViT 并不会崩掉,而是只会在准确率上有一个微小的降低(比如1-3%个点),所以不好发现。CNN 训练的时候,不太会有这种问题。他们为了解决不稳定的问题,「将ViT 的最开始的给图片分块的层 patch projction 固定住了」,并且实验上看是确实会更好的。 这点我在想是不是transformer本身就是一个比较 fragile 的结构,我们最近在训 ViT 的时候,也发现很容易炸。再往前追溯,在19年复现 Bert 的时候,也花了很多精力来调参,「可能 Transformer 是一个超参敏感的结构」? MoCo v3作者把这个工作称为 MoCo v3了,其实没有新的东西,就是有个名字好听点?可以方便称呼这个工作。用的还是一样的套路,一张图片,做两个random data augmentation,然后过两个encoder,然后算一个InfoNCE 的loss,这部分有兴趣的朋友可以找一下SimCLR、MoCo v1 v2 等paper来看看。 InfoNCE 的公式: MoCo v3 的 伪代码:
MoCo v3 在Resnet 的setting下,也还是比MoCo v1 v2 好一些的。「主要原因是什么呢?」 下图是在resnet setting下,MoCo v3 和v2 的对比
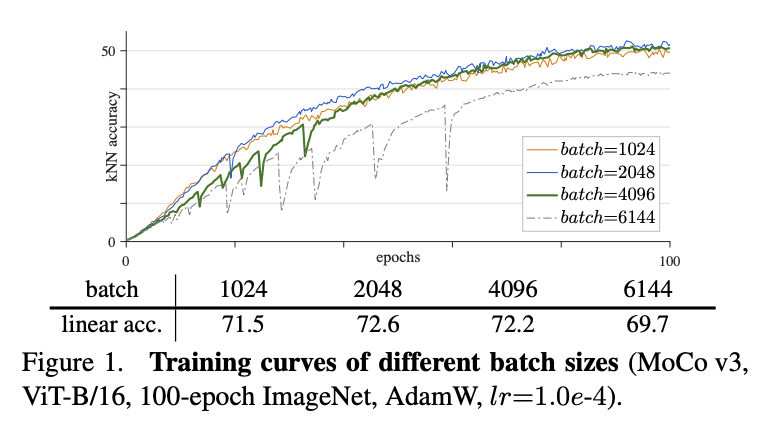
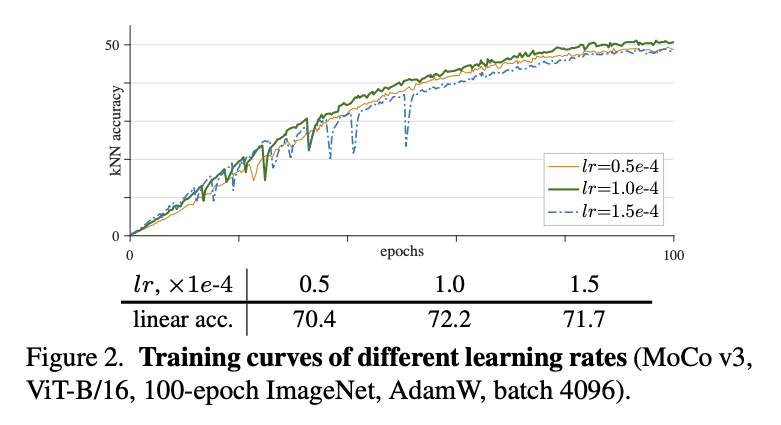
这部分开始比较有意思了,开始讲怎么训练一个稳定的 ViT。作者的说法是,ViT 的不稳定,不会体现accuracy上,实际上不稳定的 ViT 也能拿到一个看起来还凑合的准确率。这就比较难办了。然而顶级研究者还是nb,「他们用 kNN curve[2] 来监控训练是否稳定」。 Batch size & learning rateBatch Size 和 Learning Rate 是一对好伙伴,要一起看。因为一般learning rate都会根据batch size 做一些scale的操作。这里也不例外,用的是最经典的setting:「lr x batch_size / 256」。 在base LR 一定的情况下,batch size越大,反而越挫。4096 和 6144 会比2048这些要差。在batch size一定的情况下(4096),learning rate 太大不行,太小也不行。这个就是overfit和underfit的问题了。
lr一定,效果最好的是batch=2048,越大越挫
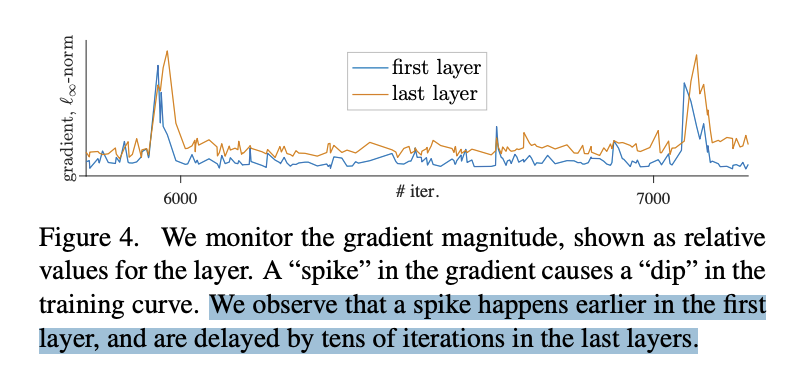
batch size一定,Lr 也比较敏感,在1e-4的时候最好 optimizer一般都是会选 AdamW 来做优化器,作者还比较了一下 LARS,在好好调了一下,能微弱涨0.1个点。「但是LARS对LR太敏感了,调一下很容易挫」,所以最后作者还是选了AdamW。我们之前还试过Adam和 SGD,在 ViT 的setting下也是比AdamW 挫一些。值得一提的是,Resnet 的setting下,SGD一直是yyds。 kNN Curve这一部分作者没有细讲,但我挺感兴趣的,翻了一下对应的论文。其实就是一个无需训练的分类指标。 做法就是,每个epoch结束之后,用当前的参数对整个test set进行编码得到embedding,然后每条数据和所有数据都算cosine相似度,召回top k,做一个weighted的投票来预测当前这条数据的类别。 「用kNN classifier Curve的好处就是,可以极其高效的看模型的效果」。可能会问,为什么不直接看train 的指标呢?因为train的指标容易过拟合。其实在有监督的setting下,是没有这个问题的,因为有监督的setting下,每个epoch结束可以直接看val集的acc。但这里是自监督的setting,没法直接看下游的acc。 Tricks on StabilityOK,讲完 ViT 训练不稳定之后,一个自然的问题就是,怎么让他稳定啊。一般遇到这么虚的问题,感觉都挺不知所措的。这里开始展现作者的功力了,作者将训练时每一个iteration的网络的每一层的gradient都记录了下来,如下图。「发现在训练的过程中,梯度会有一些尖刺。而且往往是第一层先出现,然后过几十个iter之后,最后一层会出现。」
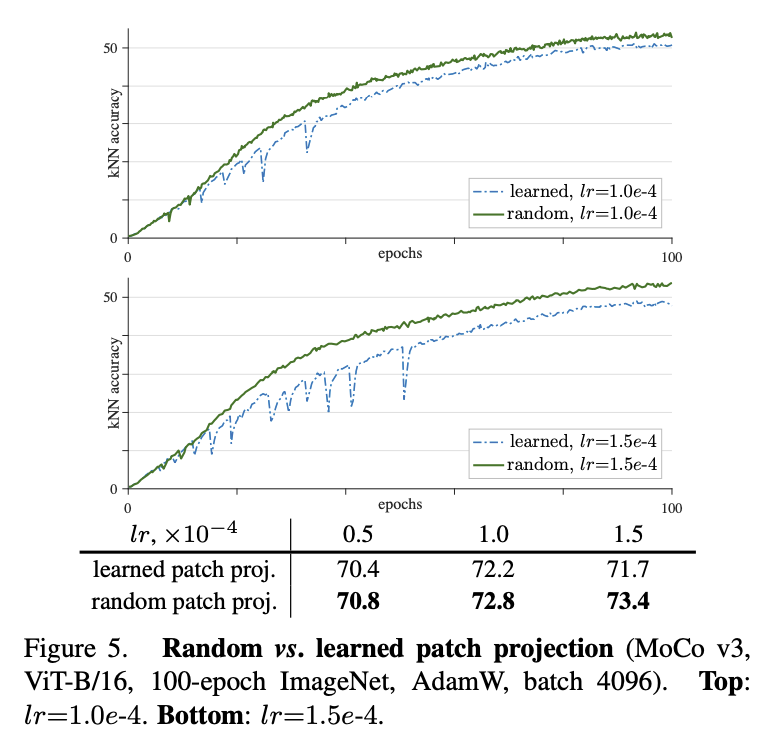
在这个观察下,作者提出了一个假设:「训练不稳定是发生在训练时前面几层浅层网络上的,然后才慢慢衍生到后面层。并提出一个大单的做法:将第一层patch projection 层固定住!」 看到这我还是挺吃惊的,毕竟在没训练的情况下,第一层patch projection是随机初始化的,这是要把一个随机初始化的参数冻结住,让网络学习一个随机层映射出来的表示??好大胆的想法。结果证明,确实冻结住第一层会可以稳定训练,如下图:
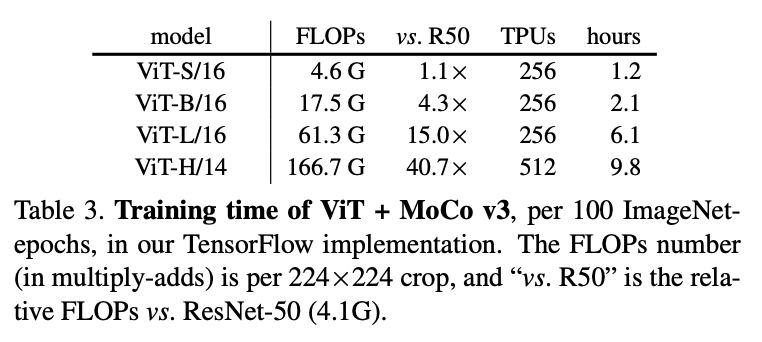
作者还尝试了其他的自监督方法,SimCLR、BYOL,fix random patch 这个trick也是work的。还在 SwAV 上试了一下,SwAV 的好处是,他的不稳定是直接nan loss(这个挺好的),然后这个trick依旧work。总而言之,「fix random patch 对所有自监督框架+ViT setting都有效」。 作者还试了可能能增加稳定性的方法,比如BatchNorm、WeightNorm、gradient clip。前两个norm没有用,gradient clip在很小的情况下有用,但很小的情况下就等价于fixed住了。 如何思考fix random patch 这个 trick 看起来,确实不太直观而且很大胆,毕竟是把一个随机参数冻结住了... 你说你先随便怎么训练一下,然后再冻结一个训过的参数也好啊... 当然了,作者也说了,「fix random patch 不能解决训练不稳定的问题,仅仅只是缓解。」 而fix 第一层,也仅仅只是因为他是唯一的非 transformer的层。看来还是任重而道远。 抛开fix random patch 这个idea 本身,让我感悟比较深的是,这个idea 作者是如何想到的,因为我在细品这个idea之后,觉得自己决对想不出这样的点子,就算想出来了也不会实施,因为冻结一个随机参数听起来实在不靠谱。这里就有认知差距了,我们捋一下作者是如何提出这个观点的: 「如何debug模型」:因为是自监督训练 ViT,没法直接看效果不好debug。所以想到了用kNN classifier Curve 的方法来看中间效果。发现训练中间确实会有偶尔 acc 猛掉的情况。 「如何观测」:那我们看看训练的gradient怎么样,于是把训练中网络各个层的gradient 可视化,发现确实会偶然炸毛一下。发现第一层炸毛之后几十个iter后最后一层会炸毛。 「提出假设」:那么自然的假设就是,第一层的参数可能是导致训练不稳定的原因。 「设计实验」:既然第一层是“罪魁祸首”,那就试试把他冻结住会怎么样了。于是就有了这篇文章。 把整个推理过程捋顺,你会发现,这个蹊跷的trick其实是很solid的尝试。可谓心思缜密,胆大心细,务实敢为,不设限,令人佩服啊。让我不禁感慨,深度学习真不是炼丹,是有逻辑的。 其他细节还有一些实现细节,把一些有启发的点记录一下。 作者对lr和weight decay做了超参搜索,用100个epoch的结果,搜到最好的再训更久。 用的40 epoch warmup + cosine LR decay。 cosine position embedding 比 learned position embedding 好0.4个点,比不加只有1.6个点 ViT-B 的setting,128TPU 跑100个epoch 仅需2.1h。有钱真好。他们的Pytorch 多GPU实现,24小时+128GPU 训练100个epoch。ViT-B/16的设定。是一个验证代码训练性能的benchmark了。而且这么看,TPU 比 GPU 真的高效很多? 小模型ViT-S 训练更久效果会好,大模型ViT-B 训练更久效果提升不那么显著 模型越大效果提升不明显,和NLP上不一样。一个解决办法当然是增加数据,但作者也觉得,有可能是因为当前的instance level的pretext task 太容易了。虽然已经论证了当前这种Constractive 的任务效果要比auto encoding的好,但可能还有更好的vision 任务呢。 写在最后这篇paper整体看下来,比较值得一提的点就是fix random patch 了。第一次初略看完paper的感慨是,现在发paper 真简单啊,就这么一个简单的 trick 就能写成paper了?第二次细看完 paper 的感慨是,这样的 trick 也不是一般人敢想能做出来的,还是厚积薄发。而且看看人家实现 setting 里动辄 256个TPU 的数量,还是很贵的。 不过不管怎么说,这篇paper 还是很值得一读的。「务实敢为,务实在推论过程严谨,敢为在冻结住随机参数这种骚操作都干做。」
顺着这个思路再延伸一下,其实看paper看到后面,一是从中汲取一些有启发的idea,第二也应该学习一下这些顶级研究者们是如何思考问题的。 抛开文章本身,「更有趣的是作者是如何严谨的一步步进行观测做出假设设计实验验证观点的」。授人以鱼不如授人以渔,汲取文章观点只是鱼,学习别人如何思考问题是渔啊。 idea总会被新的idea打败,但找idea的方法总不过时。 一起交流想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),关注公众号回复『入群』加入吧! 本文参考资料[1] An Empirical Study of Training Self-Supervised Visual Transformers: https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2104.02057v1 [2]kNN curve: https://arxiv.org/pdf/1805.01978.pdf - END -
[211渣硕] 腾讯/阿里/携程 详细NLP算法实习 面经 2021-04-19 
收藏 !机器学习基础图表 2021-03-30 
无心插柳 | 聊聊我的 ACL2020 论文 2021-03-11 
业务,工程和算法的互殴现场 2021-03-03 
|


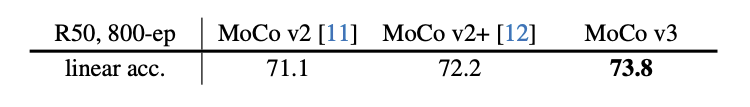



【本文地址】
今日新闻 |
推荐新闻 |